Benefits of significance testing are that the results can be computed at low cost, the theory is easy to learn and the knowledge is broadly available.
Unfortunately significance tests come with many flaws, that prevent the large-scale adoption of experimentation across marketing teams that is required to learn, optimize and innovate at pace and to ultimately succeed in today’s highly competitive and saturated markets:
1. Complicated setup: Significance tests require the specification of significance level, power, and effect size, which are often complicated to determine before running the test.
2. No test peeking: Significance tests require a certain, pre-defined amount of observations to become conclusive. It’s not allowed to look at the results before the end of the test period, which leads to long test periods, even if the result is clear early on.
3. Limitations: Testing more than two variations (A/B/n or multi-variant testing) requires a lot of additional observations to become significant, which leads to even longer test periods.
4. Results not meaningful: In the best case the result of a significance test only confirms that the effect size which was tested for is probable, while it can also be greater - it does not quantify how big the actual effect is.
5. Inconclusive results: Inconclusive test results happen regularly and require re-running the test with different parameters from scratch, which wastes time and resources.
6. Dependencies: To setup and analyze significance tests marketers usually have to depend on restricted external or internal data science resources.
7. Misinterpretation of results: More than 800 scientists recently signed an article on Nature Research that wants to stop the misuse of significance tests and p-values as they are vastly misunderstood, and oversimplify results by reporting just the p-value. Their research shows that 51% of the analysed articles confuse “non-conclusive results” with “no effect”.
Fortunately there are alternatives available. Advancements in data science, and the ability to crunch large data at affordable cost, have brought alternatives to significance tests to the table.
At Admetrics we combine Bayesian statistics with machine learning algorithms to generate actual meaningful results faster, while overcoming all the mentioned flaws of traditional significance testing. The results do not have to be interpreted and are immediately actionable:
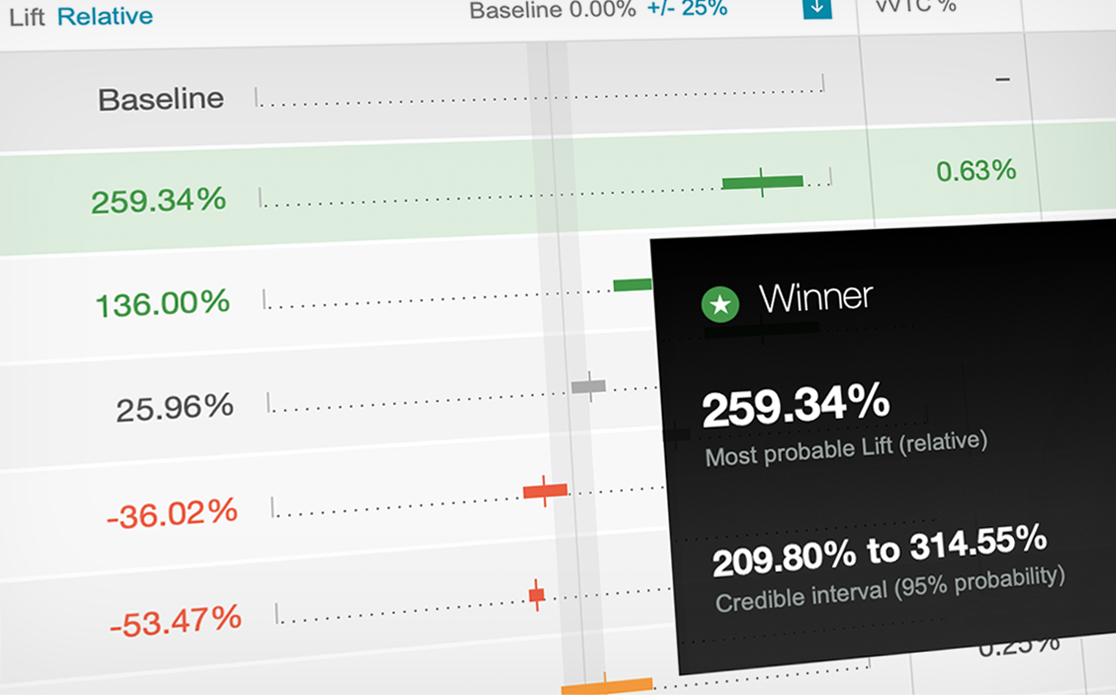
A clear winner is called out across a large set of variations by showing the most probable lift with 95% certainty. Users can also see the relative performance of all other challengers and how solid their results are.
These much more modern testing methodologies yield powerful benefits over traditional significance testing to users, such as:
- Getting conclusive results by requiring up to 10x less data/observations/time
- Switching and introducing variations at any time while results always stay accurate
- Running tests across any number of variations at once (A/B/n, multivariate tests)
- Getting more meaningful results through credible intervals
- Providing the quantified lift between specific variations (or control groups)
- Having the ability to peek into tests at any given time
A whitepaper on this topic and more information on how we solve these issues with our experimentation engine Quantify can be found here. A video including more details about how to leverage Bayesian statistics in marketing analytics can be found here.