The basic approach for understanding profitability of your marketing activities is comparing all your investments with all of your returns, and arrive at return on investment (ROI) as a good measure: Revenue divided by spend.
Maybe at first you compare monthly revenue with monthly expenses. But then you realize that most of the value of your company is in your customer equity: the sum of all future revenue you receive from all of your customers.
From this perspective, you will want to know each total and remaining customer lifetime value (CLV), and compare it with the cost (of acquisition, of ongoing support, of cross- and upselling revenues). Obviously, a big customer merits more investment. On the other hand, a lot of easily acquired customers with lower support requirements may be more profitable after all.
At first, you will be shooting in the dark, which will lead you to experimentation: Try several things, see what works (using ROI). You will try to dig into your data, which will lead you to segmentation: Which customer characteristics correlate with high CLV? Which marketing channels produce such customers? What is the cost per acquired customer (CAC) for each channel? Admetrics Quantify, part of the Admetrics Data Studio, offers an entire toolbox to answer such questions, using advanced statistical techniques to ensure optimal use of all the data you have.
The Crystal Ball
The challenge with this approach is to actually understand what the customer lifetime value is. It’s all well and good to pick some of your oldest customers, look at how they developed and how much revenue they generated to date.
But how do you transfer this knowledge to new customers? What about those who dropped out and are now longer your customers? After all, a stylized fact of life is that if you look at a cohort of customers (that is, a group with similar characteristics, such as when they became your customers, or how the were acquired, or demographics, or anything else you know), the cumulative revenue chart of the cohort looks roughly as follows, it flattens out:
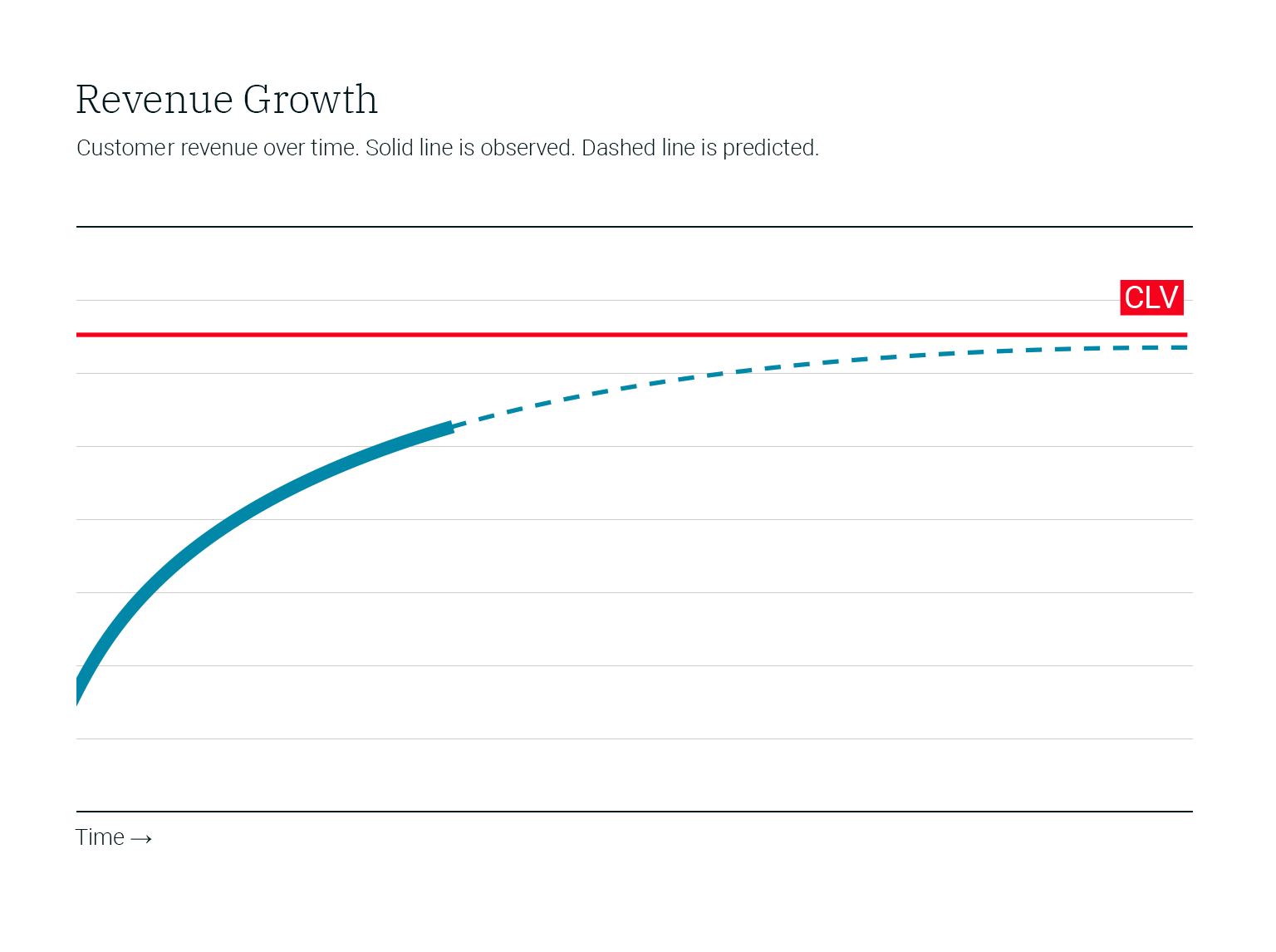
Underlying the chart are some more details:
- each customer has a somewhat different value
- at some point in time, each customer leaves (most quite early, some very late)
Fundamentally, this is a prediction problem: How do you put together long-term knowledge about established customers with short-term knowledge about recent customers to get a prediction that is:
- sufficiently precise, yet
- manageably complex to calculate
By pCLV we denote any notion of CLV that is based on predictions. Combined with spend (which is typically much easier to determine), we arrive at pROAS (predicted return on advertising spend) or more generally pROI (predicted return on investment, for some definition/selection of return and investment).
Let’s have a look at some approaches to calculate pCLV, ordered by increasing complexity.
A Wrong Approach
It is a fool’s errand to attempt to predict individual revenue events contributing to CLV on a per-user level (for instance, with regression models, or “deep learning”), for two reasons:
- customer spend behaviour is erratic, in other words, there is noise in the output data of the “prediction machine”
- there is sparsity in the input data of the prediction machine, short of intrusive methods such as interviewing each customer individually
Successful approaches attempt to either:
- model the CLV of a segment/cohort of sufficiently many customers so the individual noise cancels out. Equivalently, this means they model the average CLV of the segment/cohort, since:
total CLV of segment/cohort = (size of cohort/segment) x (average CLV per customer)
- attempt to predict, on a per-customer level, a bucket of CLV (e.g. low, medium, high) that customer may fall into. Another term for this is predictive segmentation.
Simple Approach 1: Rule of Thumb
The “MVP of models” is to simply pick an old cohort (group of long-standing customers), chart their cumulative revenue by customer age as in Figure 1 above, and pick two time frames, “short” and “long”:
- “short” should capture the initial chunk of revenue most customers contribute
- “long” should capture the majority of revenue contributed by persistent customers
You might come up with choices like 7 days and 90 days or 1 month and 1 year - this is highly dependent on your industry and business model.
You will obtain a multiplier given as:
(Revenue in long timeframe) / (Revenue in short timeframe)
The rule of thumb with a new cohort is then to simply multiply its known revenue after the “short” period with the multiplier given by the reference long-term cohort.
Simple Approach 2: Short-Term ROI
This approach completely avoids the question of predicting CLV.
Say you need to make a decision between two, three or more choices, but you currently have no other options (e.g., you need to pick a market or acquisition channel to focus on, based on some initial exploration of some list of markets or some list of channels).
Then it is often enough to pick the “best” choice, without actually knowing how “good” it is.
For ROAS (or ROI...), the heuristic is that if short-term ROAS is better between two choices, then long-term ROAS will be better as well. And so you may simply use “short term ROAS” as criterion to reallocate future spend.
Proper Approach: Generative Predicitve Models
The idea behind generative models is to replace the real customers (with all their idiosyncrasies) with a collection of simplified/idealized “agents” that
- generate revenue events according to a statistical (“random”) process, where
- each agent has parameters of the statistical process that are unique per customer
Imagine a small armada of little mechanical robots, each spitting out coins “randomly” according to some dials one might twist.
What are core properties we’d like these agents to capture?
- frequency: how often, roughly, are revenue events
- monetary: how big, roughly, is each revenue event?
- aliveness: is the agent still active (in the literature, this is often drastically described as “dead”)
“Replacing” a customer with such a robot then means to figure out a dial setting that best approximates the customer’s behaviour.
Are there other properties we can imagine, and attempt to capture? For sure! We might think of seasonality influencing all agents in varying intensity, or we might observe tendencies of agents to “lapse” and then return to regular purchasing.
However, remember that our goal is not to model each property of each customer in excruciating detail (this we might do for very few, very profitable customers that merit special treatment). What we are actually interested in is forecasting revenue of the cohort as such (since we can tune our acquisition towards similar cohorts), and it turns out that for this, the above properties (still active? how much? how often?) are usually enough.
An Important Distinction
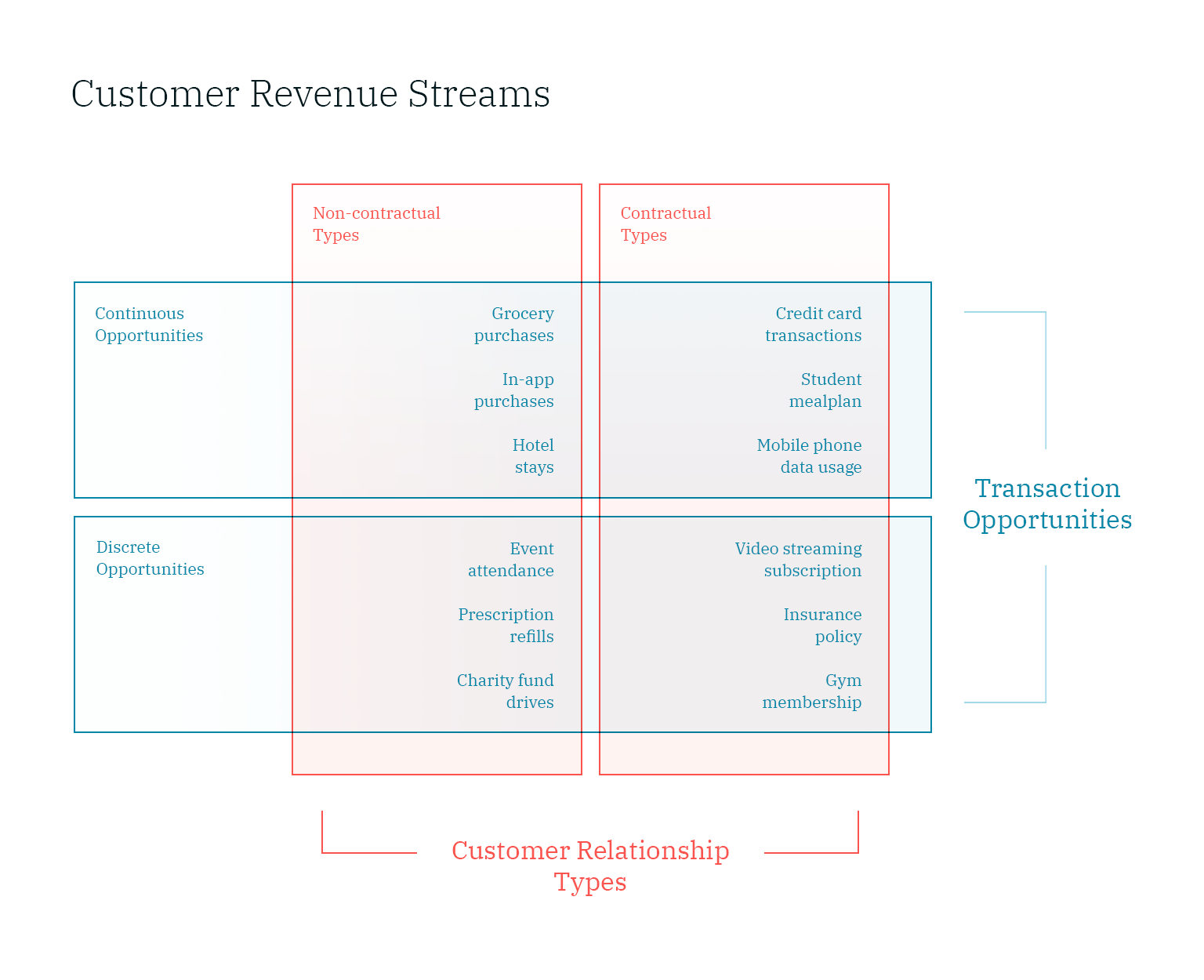
In the real world, customer revenue streams fall in two main categories:
Category 1: Contractual
The customer has a contract with the company. In terms of the core properties of the previous section:
- frequency is often fixed (e.g., there may be monthly or yearly payment schedules)
- monetary is also often fixed (there may be multiple categories, e.g. basic/pro accounts)
- aliveness: at each renewal, the customer may cancel the contract, however the company always knows the status of each customer
In terms of modeling, this simplifies the task a lot! All that remains is to come up with some process describing cancelation rates.
Category 2: Non-Contractual (or discretionary)
The customer has no contract, and may make varying sized payments at varying times. Due to the lack of contract, the company does not even know whether the customer will make another payment.
This means we need a more complex model, capturing all of the core properties in the previous section.
Multiple revenue streams may (and often do) exist, for instance in a paid marketplace there may be a contractual revenue stream (membership) together with discretionary purchases. In such a setting, we can model each stream individually, or let them inform each other (for instance, cancelation of the contractual stream implies inactivity of the customer in discretionary stream).
Reference: Probability Models for Customer-Base Analysis by Peter S. Fader and Bruce G.S. Hardie et al.
Bayesian interpretation
The models described above capture customer behaviour in terms of distributions. This makes the models amenable to a Bayesian treatment using probabilistic programming. In a follow-up blog post, we will dig into the details.
To recap: In Quantify “average values” such as clickthrough rates are enriched with credible intervals, capturing a 95% probability interval containing the “true” value, based on the size and variance in the data.
Here too, for CLV models, we can obtain credible intervals, first for the model parameters, and then as consequence for values of the forecasts. In this context, credible intervals are usually called prediction intervals.
Practically, for decision making this means that you will have a range of possible values for future revenue. If the range is too wide, this will inform you to collect more data before making potentially risky decisions.