Part I: A tale of two cohorts
So your company is selling or distributing an amazing product, app or service, and you want to do some paid user acquisition, either to test the waters with a soft launch, or to boost your ongoing operations. In this series of blog posts we will outline how to kick-off paid user acquisition and steer your advertising investments towards higher profitability.
Financials first
Ad spend is an ongoing sunk cost. It “generates” users, that as time goes on hopefully recover these costs in revenue. For instance, in the case of freemium apps, revenue streams can be in-app advertising and in-app purchases; your use case will have specific revenue streams.
The core metric that tracks profitability in user acquisition is return on advertising spend (ROAS). To calculate ROAS, users are grouped by their acquisition date into daily, weekly or monthly cohorts. Then, for a given attribution horizon (e.g., 1 day, one week, or two months) their total revenue is divided by initial ad spend and multiplied by 100%. In other words, being profitable means ROAS > 100%. Finite budgets imply that the horizon for ROAS to show profitability is limited.
Can you trust your ROAS?
Do you have enough data to justify the ROAS you calculate at face value? What does it mean to have enough data?
At Admetrics we follow a certain line of thinking:
- The user comes first: while spend is for instance reported as averaged cost per install (CPI) each user creates individual amounts of revenue, and so overall average revenue per user (ARPU) only gives a partial picture. Underlying this average is a distribution of individual revenues for each user (RPU).
- Numbers are meaningless without qualification: the more data is available (which in this case means: more users), the larger the cohorts are, and the more one can “believe” the quotient metric ROAS, as defined above. In general, by applying Bayesian statistics this calculated quotient can be reinterpreted as the most likely value (called mode) of the average of the so-called “posterior” (“after having seen the data”) distribution of individual users’ returns on ad spend. With this reinterpretation, gathering the 95% most likely of all other possible values gives rise to credible intervals, a data-driven way to qualify numbers.
These credible intervals are the core of our experimentation engine Quantify, as applied to user acquisition: ROAS (and any other metric) is not just one number, but actually a range of likely numbers. By construction, the width of this range depends in a statistically optimal way on
- the amount of data gathered, in this case the number of users observed, and
- the variance in the revenue (or other) data they display.
So the more data, the tighter the interval, but the noisier the data, the wider.
A real world example
That said, let’s have a look at some long-term real (anonymized) data, and then let’s look into ways to optimize it. We use 160 days, since that’s the data we happen to have at hand.
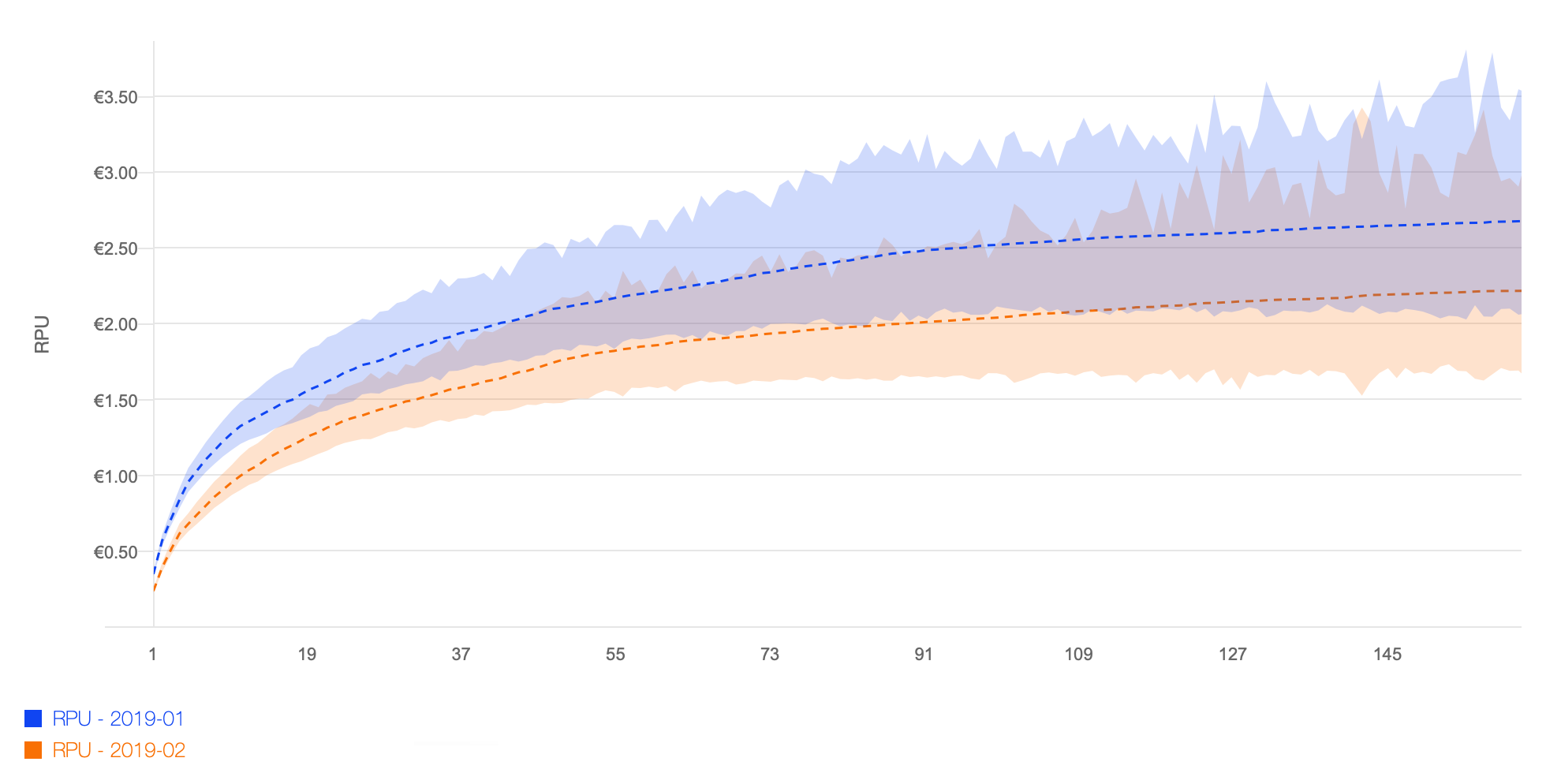
Looking first at revenue, the following chart shows ARPU (dashed lines) for two monthly cohorts (Jan 2019 and Feb 2019), as a function of cohort age. The x-axis is displayed as user age within the cohort. By charting against age instead of date, we ensure that we compare apples to apples.
Observations:
- the cohort revenue curve flattens out, as users churn from the app
- January is off to a head start that it never loses
- for longer horizons, there is more variety among individual users, so the credible interval becomes wider
Interestingly, the winner/loser relationship reverses if we take spend into account and look at ROAS (as we should):
January has a much higher user acquisition cost: 2.49 EUR vs 1.60 EUR (~55% higher than February). January also has a higher average revenue over 160 days: 2.61 EUR vs 2.15 EUR (~21% higher). Overall, February has a better ROAS: 134% vs 105% after 160 days.
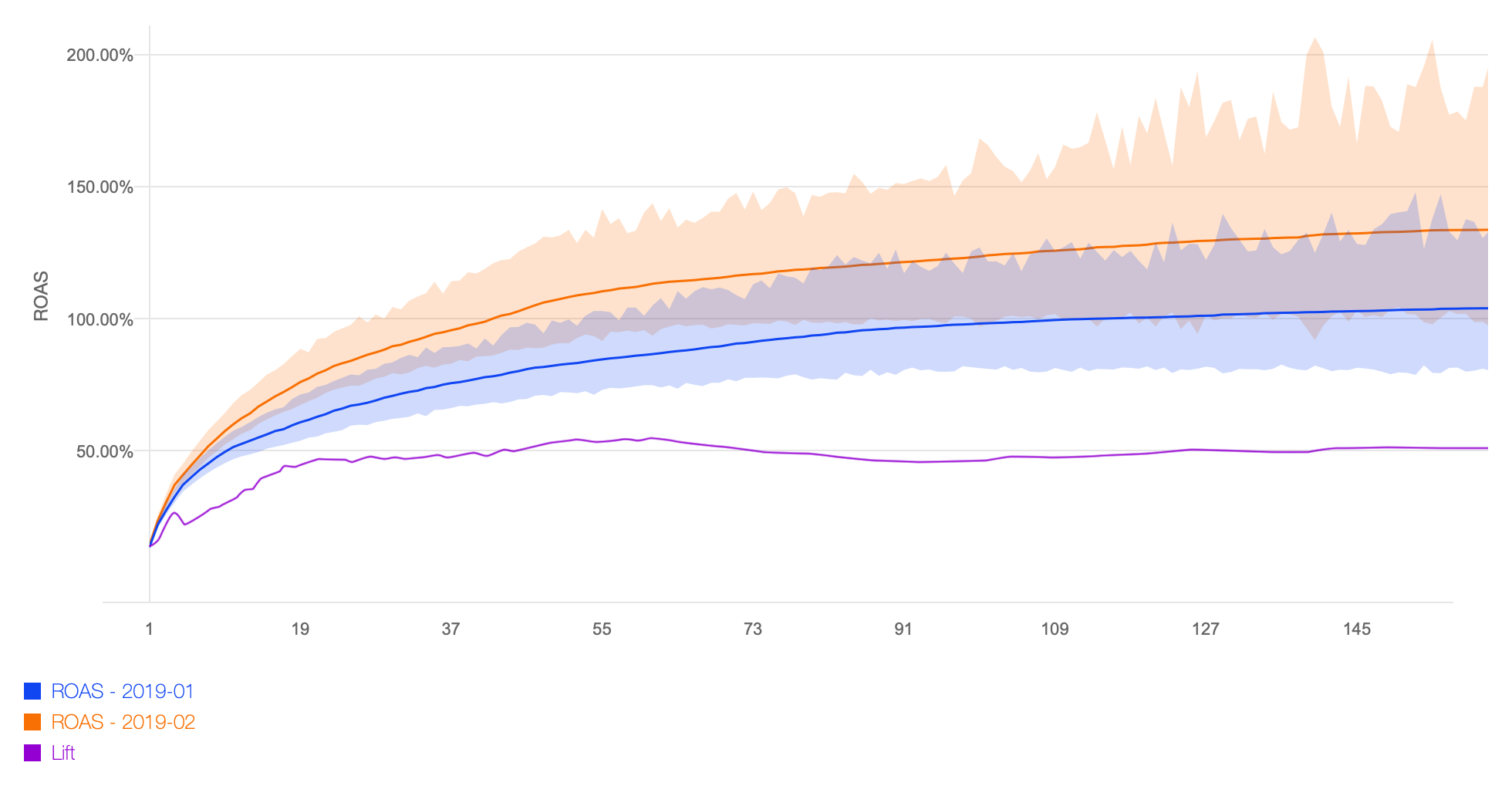
Most dramatically, February also hits profitability much faster: after 42 days, vs 114 days for January. Due to the flattening out of ROAS, acquiring the “wrong” users has a severe impact on liquidity of operational capital. So it’s important to get that right!
Now while long-term ROAS and long-term RPU, that usually corresponds to the customer lifetime value (CLV/LTV), are representing the “ground truth” financially, they are not very useful for planning feasibility of a channel, or optimizing a campaign. We define the lift of February over January as
100% * (ROAS(February) - ROAS(January)) / ROAS(January)
In our example, it’s 28.8% over 160 days. The observation is that this lift stabilizes fairly quickly (purple line).
Defining a short-term KPI for optimisation
After about 21 days, the lift is at ~26%, and stays that way, more or less. In fact, already after 7 days (1 week), it’s clear that February beats January in performance. This is a good thing: It means that we can now use the short-term ROAS to rank the performance of channels, campaigns, creatives, and targeting for optimisation.
This also makes intuitive sense: The task of user acquisition is to acquire the right users and retain them long enough to get them over the initial bump. After that, long-term customer success will depend on other factors, such as the general product quality.
It's important to understand that the appropriate notion of “short-term” will depend on your specific industry, product and marketing channel, so you will have to figure out what short-term means for you.
Stay tuned
In the next post in this series “Segmented for success” (read it here) we will:
- define your short-term KPI
- explore the levers we have available to optimize acquisition, leading to segmented cohorts
- explain how to apply credible intervals also to lifts, so we can make trustworthy decisions, based on data
- introduce additional metrics to understand what works and why